GitHub’s public timeline contains a wealth of knowledge about contributions to open source software from all over the world. It’s pretty typical to see over ten thousand contributions of some sort every hour! I decided to focus on the top 200 repositories (by forks) only in order to have a more manageable set of data. Each comment, pull request or commit is tied to a repository which in turn usually has a primary language associated with it. Contributions from folks who didn’t provide a location were ignored and OpenStreetMap’s Nominatim service was used to geocode locations into latitude and longitude for those who did say where they coding from.
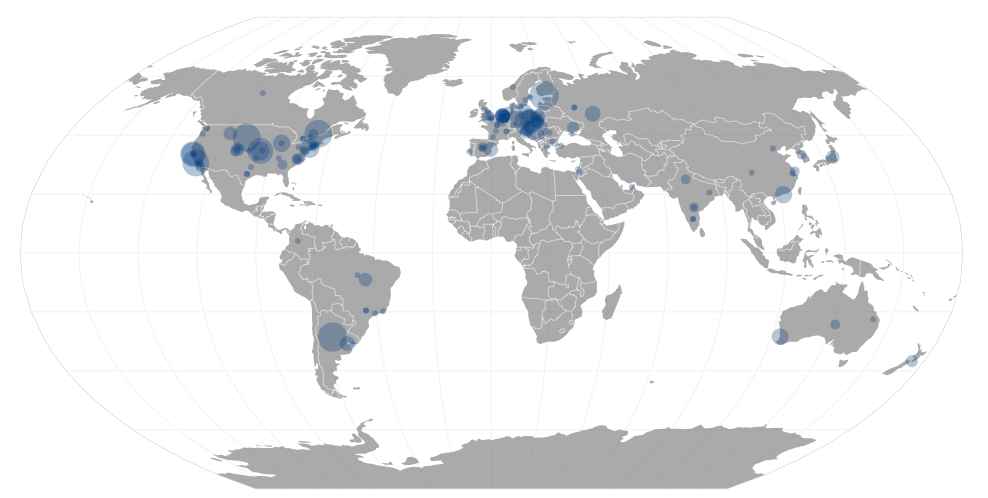
If you aren’t from New York City or San Francisco and you contributed to a top 200 repository, you can probably find your own commits if you zoom in enough.
Contributions
Not all events are created equal. Watching a repository is not the same as committing code or opening issues. In general, I tried to calculate contributions based on the same criteria GitHub uses but I think I’m not introspecting commits and pull requests as deeply as they are. Typically, for larger repositories, users commit to their own forks — which I ignore — and later send pull requests which I’m counting. However, this discounts a large fork which merged many commits to be worth the same as a one line pull request. The person who actually merges the pull request gets the same credit as the author which actually makes sense when I gave it a second thought.
One way to improve my accounting of contributions would be to look at the actual repositories to see which commits to forks ended up in the “main line”. For a repository that actually uses GitHub virtually all commits end up in the main repository through pull requests or via somebody with permission to push directly which appear in the githubarchive.org data. For a repository like Linux which only stores code on GitHub and doesn’t accept pull requests it would be nice to actually analyze the commit history. I bet most of the Linux contributors have GitHub accounts to attribute their work to.
Geocoding
Geocoding messy data is well… messy. The location field for users on GitHub is simply a fill-in-the-blank field and users can type anything in there from their city to their university to an IRC channel. Sometimes people just type in a country name which is fine for Singapore but doesn’t really narrow it down too much for Canada. The locations listed for contributors on the top 200 repositories was surprisingly clean, however. It wasn’t without somewhat humorous errors though.
Links
- GitHub repo for this visualization
- See last year’s (slightly late and not so great) entry to the GitHub data challenge
- Check out Dana Bauer’s and Idan Gazit’s PyCon presentations on analyzing GitHub data.
My entry placed third!
One note that I didn’t make very clear is that this isn’t very instructive for comparing the absolute popularity of different languages. More big Ruby projects are hosted by GitHub than C or Java projects.
Now what to do with that $50… Maybe they’ll sell me some Slow Merge.